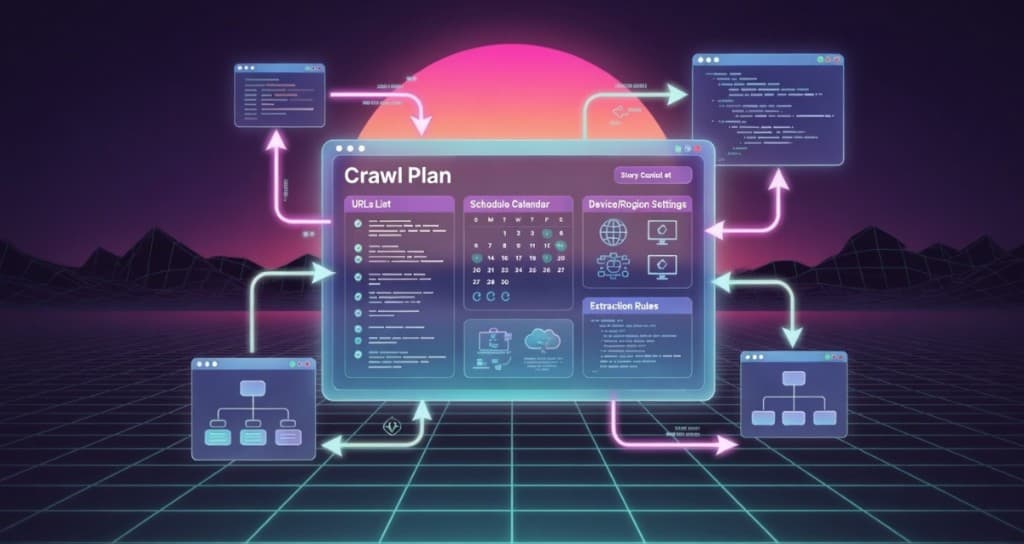
Crawl plans: scope, frequency, and consistency
Recurring web intelligence works best when you define what you're collecting, how often, and from where. That definition is a crawl plan.
What goes into a crawl plan
A crawl plan typically includes: the list of URLs or discovery rules (e.g. sitemaps, seed URLs), the schedule (hourly, daily, weekly), and the context (device type, region, or other parameters that affect what gets rendered). Optionally you add extraction rules or checks that run after each run. The goal is to make each run comparable so that trends and alerts are meaningful.
Choosing scope and frequency
Scope too broad and you pay for data you don't use; scope too narrow and you miss important changes. Start with the smallest set of sources that answer your key questions, then expand. Frequency should match how fast the real-world data changes: prices might need daily or hourly checks; policy pages might be fine weekly. Consistency matters more than maximum speed for most use cases.
Keeping results comparable
Same URLs, same schedule, same device and region settings mean you can compare results across runs. That's what makes crawl plans useful for monitoring, dashboards, and AI: the pipeline is fixed, so differences in output reflect real changes in the web, not random variation in how you collected the data.
Practical takeaway
Write down your crawl plan before you scale. Define scope, frequency, and context; run it consistently; then use the resulting data for alerts, analytics, or agent-ready knowledge. Adjust the plan as your questions change, but keep it explicit so the whole team (and your agents) know what "current" means.