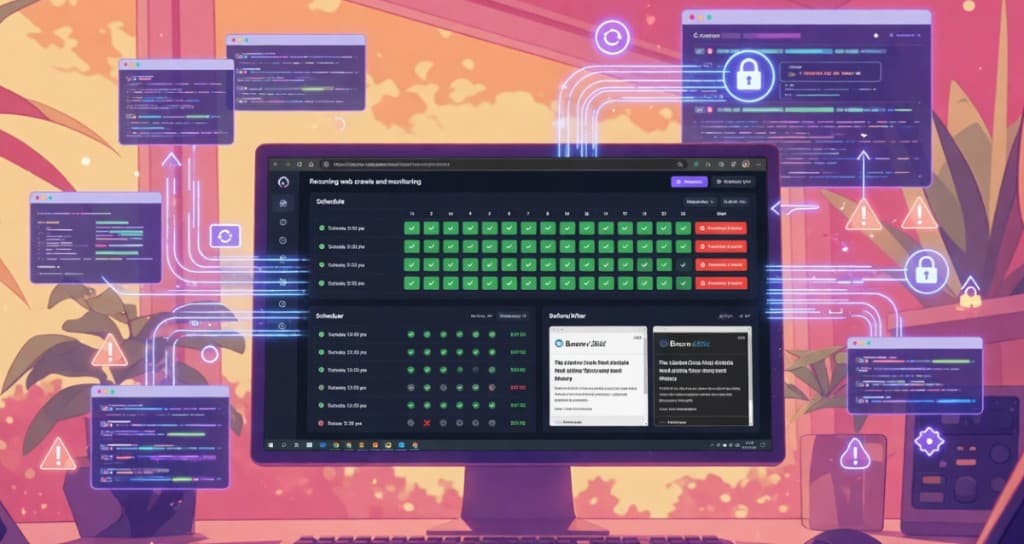
Introducing Insight Stacks: recurring web intelligence for AI
We're excited to announce the launch of Insight Stacks on UpRock: recurring web intelligence packaged as structured knowledge objects for AI agents, dashboards, and automated workflows.
What Insight Stacks are
An Insight Stack is defined by a crawl plan: what to collect, how often, and from which context (e.g. device, region). Each run produces structured data (extracted facts, metadata, and optional raw evidence) instead of ad-hoc HTML. Stacks are designed to be reused: the same stack can feed an agent, a monitoring dashboard, or an internal API. You define the stack once; we handle scheduling, capture, and delivery.
How they differ from one-off scraping
One-off scrapes answer a single question at a point in time. Insight Stacks answer a class of questions over time. Because each stack runs on a schedule, the data stays current. Because the output is structured, agents and applications don't have to re-parse pages or guess semantics. You get a consistent schema, clear timestamps, and the option to include definitions and summaries so that both humans and AI can interpret the data correctly.
Who it's for
Insight Stacks are for anyone who needs recurring web data: tracking competitors, monitoring compliance, watching prices or availability, or building agent-ready knowledge pipelines. If you've been gluing together scrapers, cron jobs, and custom parsers, Stacks offer a single place to define, run, and consume recurring web intelligence.
Practical takeaway
Insight Stacks are available now. You can create a stack from the UpRock dashboard, set your crawl plan and extraction rules, and receive structured outputs on a schedule. For more on the "why" behind Stacks, see Insight Stacks turn web chaos into reusable intelligence for AI. To get started, visit uprock.ai/insight-stacks.